
Data-gedreven werken is lang niet in elke organisatie vanzelfsprekend. Processen moeten het mogelijk maken om data in te zetten, mensen binnen de organisatie moeten met data willen werken en data moet toegankelijk zijn voor de medewerkers. Hoe ver is jouw organisatie? Hoe kun je stappen zetten om data-gedreven werken goed te implementeren?
In deze blog leggen we uit welke aspecten er meespelen in data-gedreven werken, de implementatie daarvan en welke benadering je kan volgen.
Lees meer...
Hoe makkelijk is het om data te gebruiken binnen jouw organisatie? Het antwoord hierop verschilt enorm van “ik kan direct alle data gebruiken” tot “het is sneller om een onderzoek opnieuw te doen dan om de data te vinden”. Door het gebruik van verschillende systemen is het lastig om data te delen.
Lees meer...
Afgelopen 27 september was er weer een bijeenkomst met onze klankbordgroep. Insteek van deze bijeenkomsten en is het van elkaar leren op het gebied van data en organisatie. We gaan bij elkaar langs en bespreken een case van de gastheer, om zo best-practices te delen en ideeën uit te wisselen.
Afgelopen week waren wij op bezoek bij de NS. Het was een geslaagde bijeenkomst, waar iedereen veel geleerd heeft over hoe ze hun eigen data management aan kunnen sterken. Wij en de klankbordgroep willen de NS hiervoor enorm bedanken. Bij deze bijeenkomst is gekeken naar data management en een goede borging binnen de organisatie. Data management heeft als doel het beheer van data in goede banen te leiden, maar waarom is het zo moeilijk om hier grip op te krijgen en wat is nodig voor goede borging van data?
Data management de baas worden is lastig. Er is steeds meer data van binnen en van buiten organisatises vanuit verschillende systemen. En ook de tools en definities van data verschillen vaak binnen de organisatie zelf. Voorbeelden zijn sensoren, social media, bedrijfsverslagen en metingsrapporten. Elke afdeling en discipline heeft zijn eigen data, maar gebruikt ook data van andere afdelingen. Zo ontstaan verschillende kopieën van data met een variatie in data kwaliteit tussen deze kopieën.
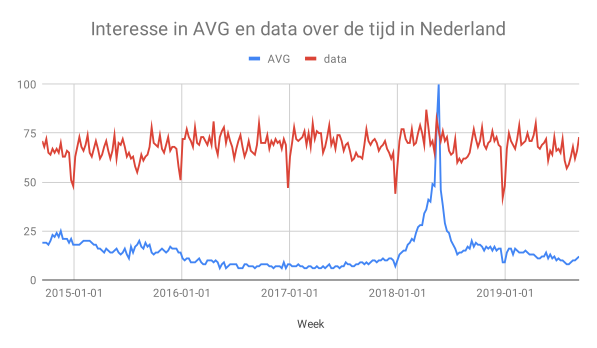
Daarnaast zijn er natuurlijk ook een hoop wetten en regels. De overheid heeft deze opgelegd om bedrijfs- en persoonsgegevens te beschermen. Een van de belangrijkste regels is, natuurlijk, de AVG. Sinds mei 2018 is deze verordening van toepassing. Als we naar informatie van google trends kijken, zien we dat er in mei 2018 een enorme piek is in aandacht voor de AVG. We zijn inmiddels in de fase aanbeland dat er geen AVG paniek meer is, maar dat we goed kunnen kijken naar gedegen implementaties binnen de organisatie.
Heel plat gezegd heeft de AVG 2 categorieën: het mag niet of het mag wel mits de juiste borging is gehandhaafd. Hoe beter de borging, hoe meer je uiteindelijk mag binnen de wettelijke kaders van de AVG. Het goed inrichten van je eigen processen en data zorgt ervoor dat je de borging van de AVG beter kunt implementeren. Maar niet alleen dat, het biedt meer kansen. Zo kun je data beter delen en de verschillende kopieën (als die er nog zijn) beter beheren. De AVG is eigenlijk een grote kans om data kwaliteit en gebruik te verbeteren!
Een goede borging van data is dus belangrijk voor de AVG. Maar niet alleen daarvoor, een goede borging zorgt dat jij makkelijker met data kunt werken en dit dus op meer vlakken in kunt zetten. Goed datamanagement is hiervoor cruciaal.
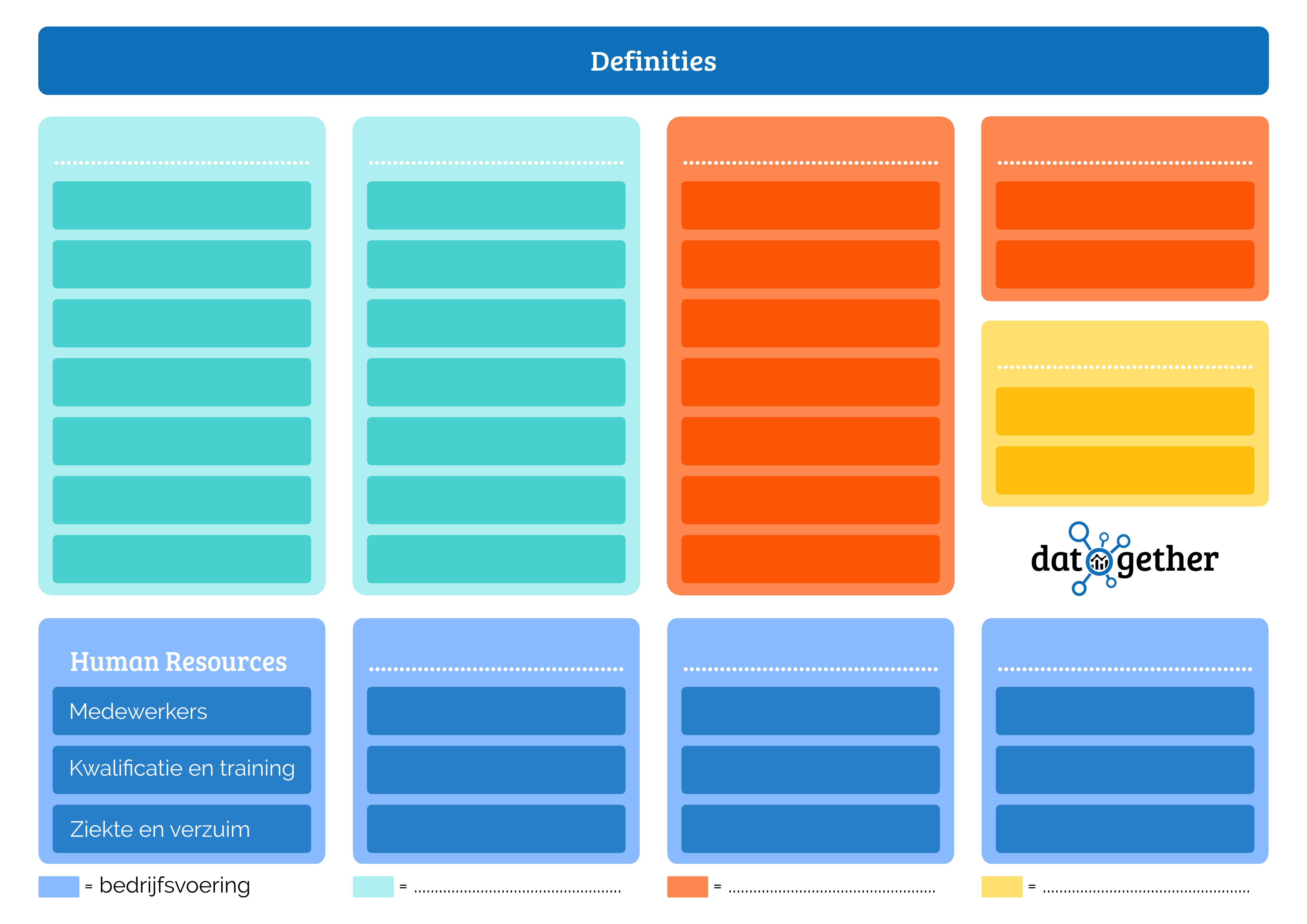
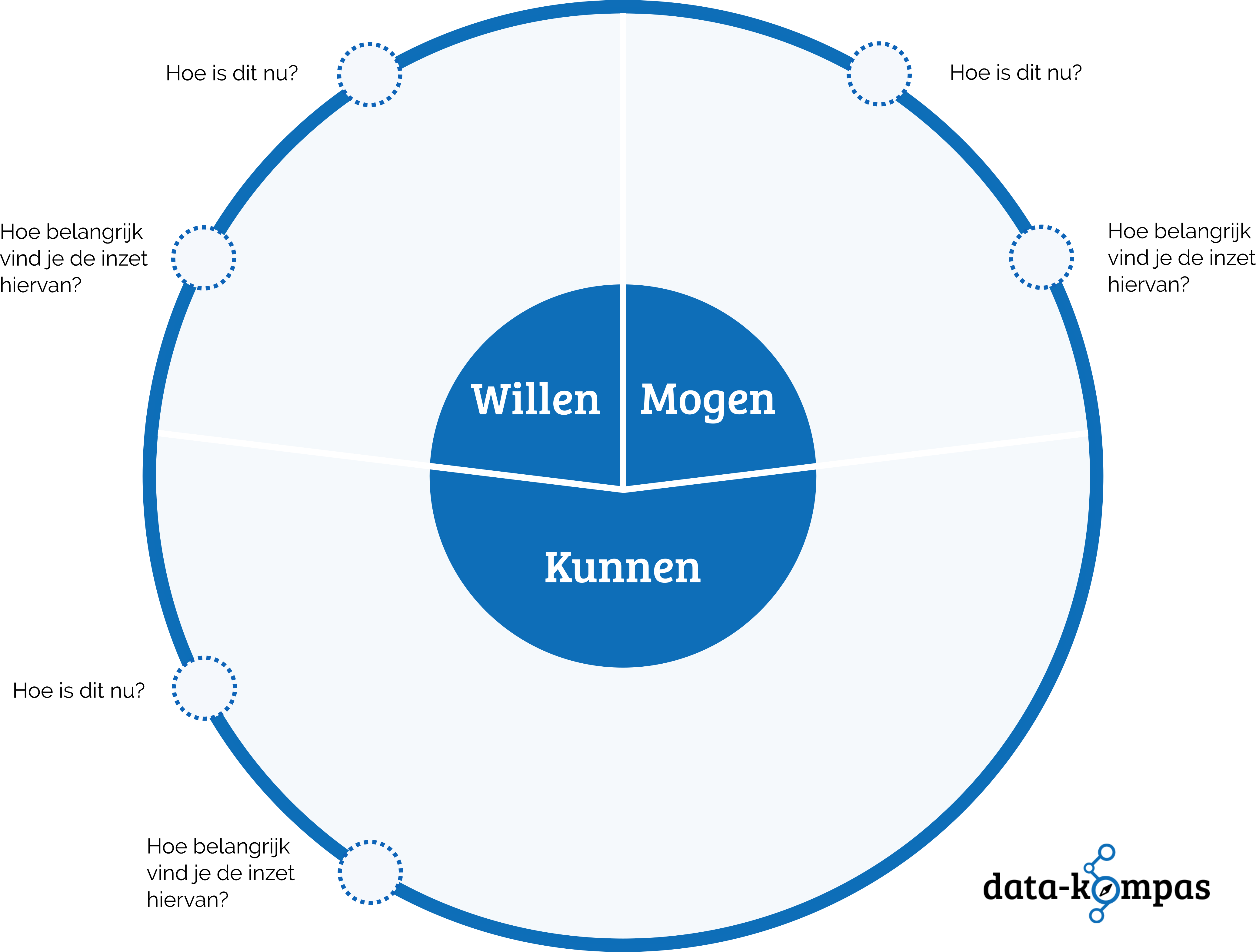
Data management is de balans tussen het met data willen werken, met data kunnen werken en duidelijk hebben wat met de data mag. Een juiste balans tussen wat je mag, kan en wil is stelt je in staat data-gedreven werken.
Hoe zit dit bij jouw organisatie? Hiervoor kun je naar deze elementen kijken: Hoe graag willen de mensen binnen jouw organisatie met data aan de slag? Wat doet jouw organisatie om het willen te verhogen? Hoe makkelijk is het om data te gebruiken binnen jouw organisatie? Welke concrete acties onderneemt jouw organisatie om de toegankelijkheid van data-gebruik te verbeteren? Weet jij duidelijk wat er mag binnen jouw organisatie?
Vervolgens kun je antwoorden op deze vragen voor jouw organisatie samen brengen in één figuur. In de grote vlakken kan je neerzetten wat je met data wil, mag en nodig hebt om het te kunnen.
Op elk van deze vlakken kun je een snelle check uitvoeren. Hoe staan we ervoor op dit punt? Kunnen we heel veel, maar wil eigenlijk niemand er mee aan de slag? Of willen de meeste wel, maar kan er niets met de data omdat het beheer niet op orde is? Elke organisatie heeft zijn eigen profiel tussen willen, kunnen en mogen.
Om meer met data te kunnen is data kwaliteit van cruciaal belang. Om meer inzicht te krijgen in welke data beschikbaar is, kun je een ‘datalandkaart’ maken. Hierin krijg je overzicht in waar binnen de organisatie welke data beschikbaar is. In een volgende blog gaan we hier uitgebreid op in! Hou onze blog in de gaten voor de nieuwste updates.
Op welke vlakken van willen, kunnen of mogen kan jouw organisatie zich het beste ontwikkelen? Wij helpen je graag om dit duidelijk te krijgen en hier de eerste stappen mee te zetten. Neem contact met ons op voor de mogelijkheden.
Lees meer...
Sinds 25 mei 2018 is in Nederland de AVG van kracht. De stricte regels en richtlijnen hebben nog steeds een gigantische impact op hoe organisaties met hun data omgaan. Voor een goede implementatie van de AVG is goed beeld nodig voor data opslag en eigenaarschap van de data binnen de organisatie.
Lees meer...

Data is een goudmijn waar veel nieuwe inzichten uit gehaald kunnen worden. Data-gedreven werken zorgt voor betere metingen van de huidige situaties, eerdere signalering van problemen, betere preventie van problemen en meer mogelijkheden voor samenwerking. Data-gedreven werken kan hiermee het Agile werken versterken.
Lees meer...

Open data wordt steeds toegankelijker en makkelijker te gebruiken. Gebruik, analyse en interpretatie van deze data kan je veel inzichten geven voor beter beleid en strategie binnen je organisatie. Eigenlijk is open data de openstaande deur naar betere beslissingen. Hier volgen 3 redenen waarom iedereen met open data aan de slag zou moeten gaan.
Lees meer...

Vandaag is in Den Haag the Youth for Climate mars gaande. De mars laat zien, dat veel mensen de verdere klimaatverandering willen voorkomen. In Nederland hebben we al stappen gemaakt, wat hieronder te lezen is. Gemeentes hebben hier ook ambities over, zoals gemeente Zeewolde een energieleverende gemeente wil worden (Energievisie Zeewolde van 16 maart 2017). Het lijkt erop dat zij dit ook daadwerkelijk gaan halen. Ook andere gemeenten doen veel om hun energieambities te halen. Daarom hebben wij het mogelijk gemaakt om dit voor je eigen gemeente te ontdekken, in onze nieuwe energieambitie tool.
Lees meer...
Elke organisatie heeft tal van uitdagingen. Door complexiteit van de omgeving en de opgaven zelf is het lastig om een compleet beeld te vormen, wat concreet sturen lastig maakt. Door middel van een omgevingsanalyse is het mogelijk om completer te kijken naar de uitdaging en een kapstok te vormen voor verder data-analyse, interpretatie en sturing.
Lees meer...

Veel mensen zijn er wel van overtuigd dat data de toekomst is, en dat het belangrijk is dat er iets met data binnen de organisatie gedaan wordt. Maar wat zijn nu concreet de voordelen? Waarom zou je beginnen het het implementeren van data-gedreven beleidsplannen? Wij geven hier de 3 grootste voordelen.
Lees meer...
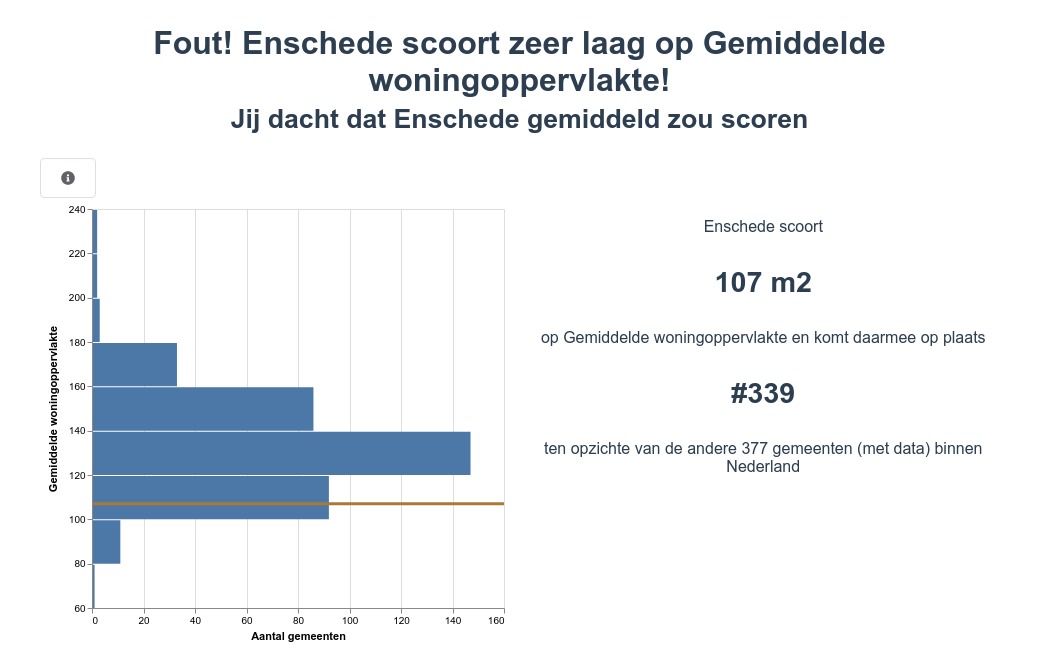
Weet jij hoe de gemiddelde woningoppervlakte binnen jouw gemeente is ten opzichte van andere gemeenten? Weet jij hoe jouw gemeente scoort op afvalscheiding? Bekijk het op Hoe scoort mijn gemeente vandaag.nl”
Lees meer...

Ga jij altijd op je intuitie af? Of doe je altijd eerst gedegen onderzoek voordat je een beslissing neemt? Of neem je alleen beslissingen op basis van metingen van anderen? Hoe mooi zou het zijn als je het beste hebt van beide werelden? Hoe kun je data gebruiken om jouw keuzes te wegen, te valideren en om je blinde vlek te ontdekken?
Lees meer...

Data-Kompas maakt het eenvoudig om vele open data bronnen te bekijken en je eigen data hiermee te combineren. Je kunt dus snel inzicht krijgen in specifieke cijfers voor de relevante vraagstukken voor uw eigen organisatie. Desalniettemin kan het lastig zijn om de eerste stappen te zetten. Daarom leggen wij vandaag in deze blog uit hoe je kunt starten met Data-Kompas en hoe je de eerste resultaten boven water tovert.
De gratis versie is voldoende om deze tutorial zelf ook te doorlopen. Log in, of meld je aan op app.data-kompas.nl en volg onderstaande stappen naar je eerste data-analyse!
We beginnen met een voorbeeld: een vergelijking van het aantal bijstandsuitkeringen binnen gemeenten. De eerste stap om hier een overzicht van te verkrijgen is door op het “dataset” tabblad te klikken (2e blauwe tablad met het icoontje). Dit tabblad geeft een overzicht van alle datasets die beschikbaar zijn voor uw account.
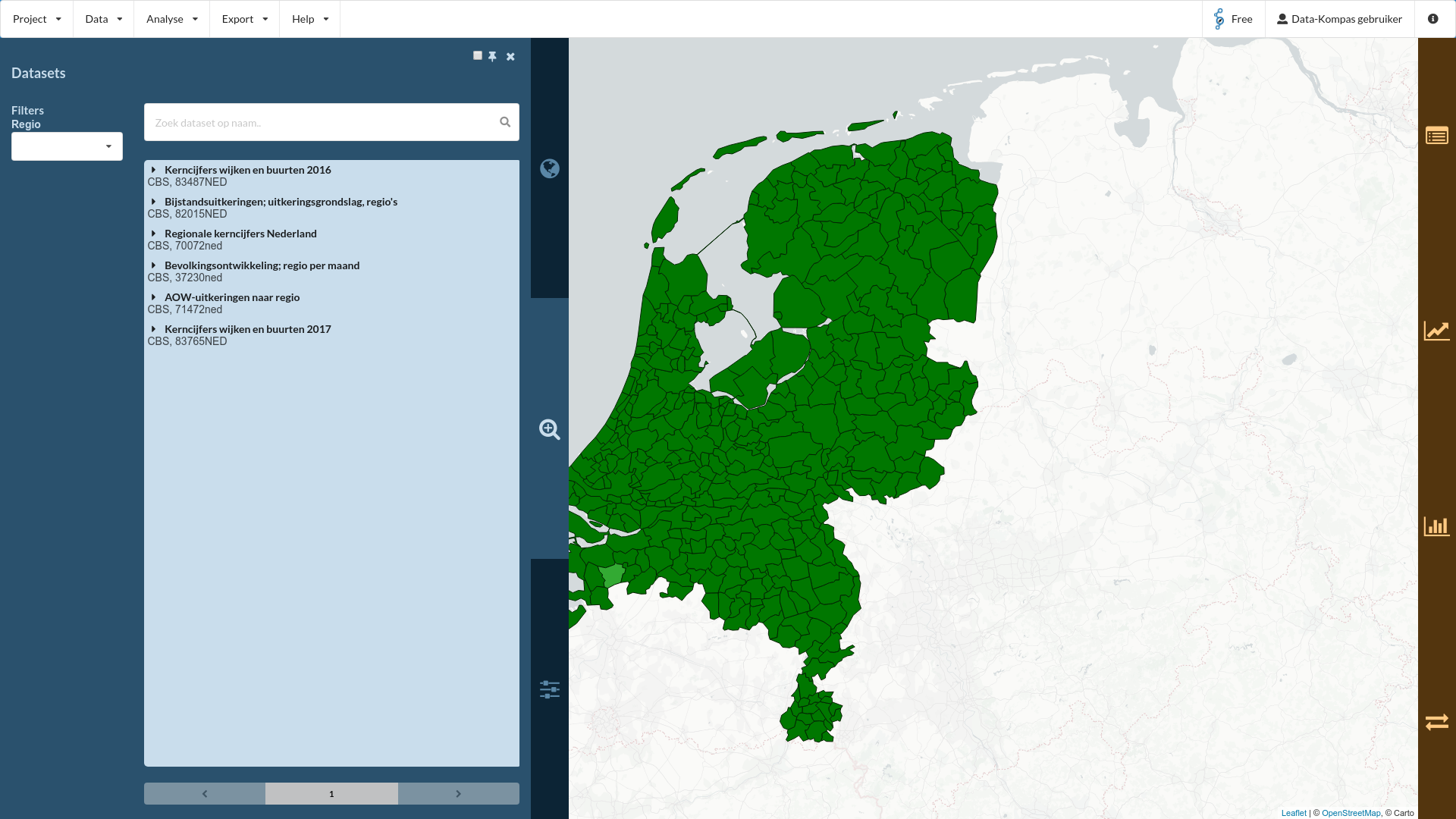
Wij zijn geinteresseerd in de dataset “Bijstandsuitkeringen; uitkeringsgrondslag, regio’s”. Door hierop te klikken zien we de elementen die beschikbaar zijn in deze dataset. We zien een indicator “Aantal bijstandsuitkeringen”, en een groep indicatoren “Uitkeringen naar uitkeringsgrondslag”. Klik op “Aantal bijstandsuitkeringen”. De data wordt ingeladen en de kaart kleurt nu naar het aantal bijstandsuitkeringen per gemeente. Zo makkelijk is dus de eerste visualisatie!
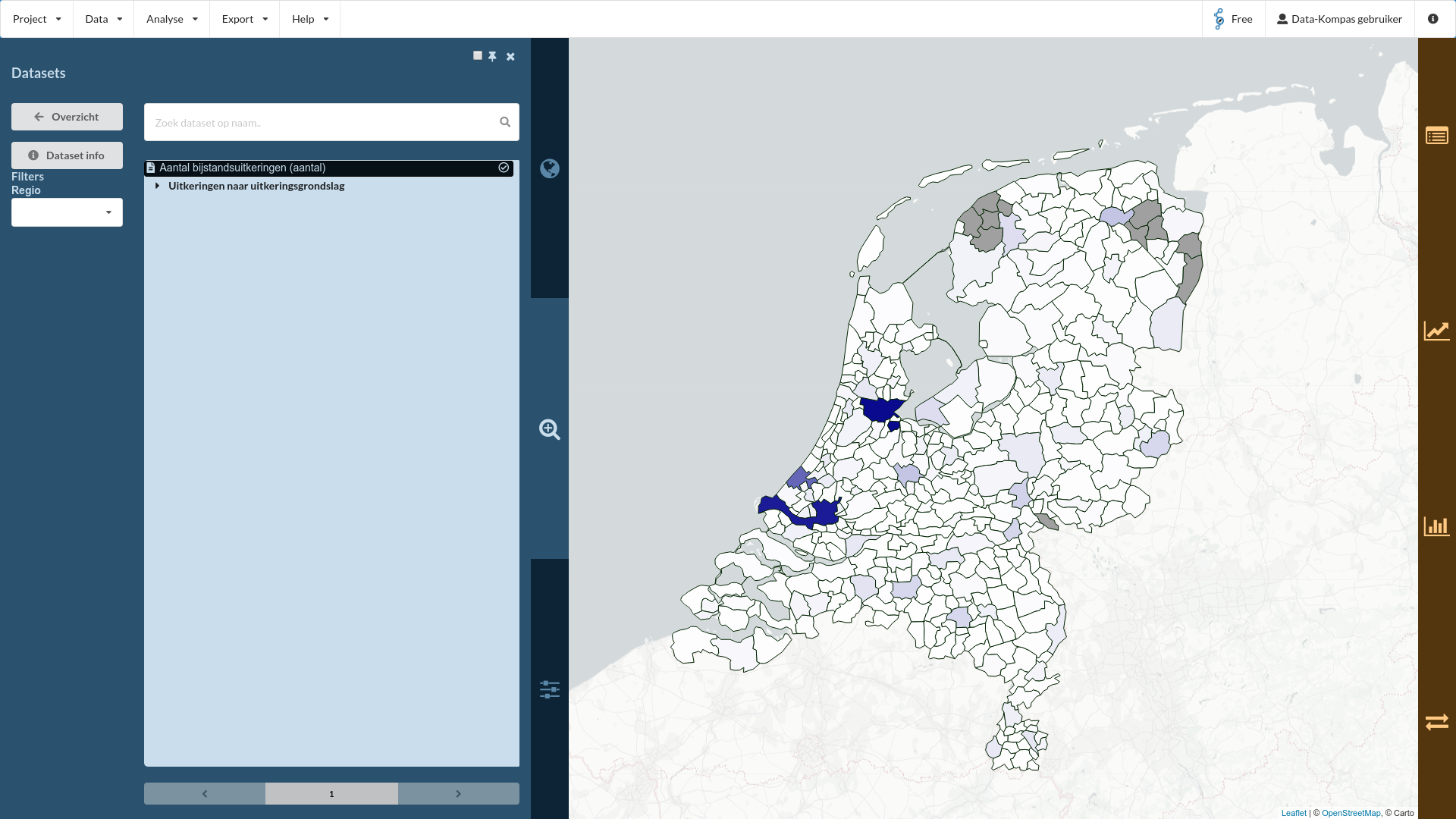
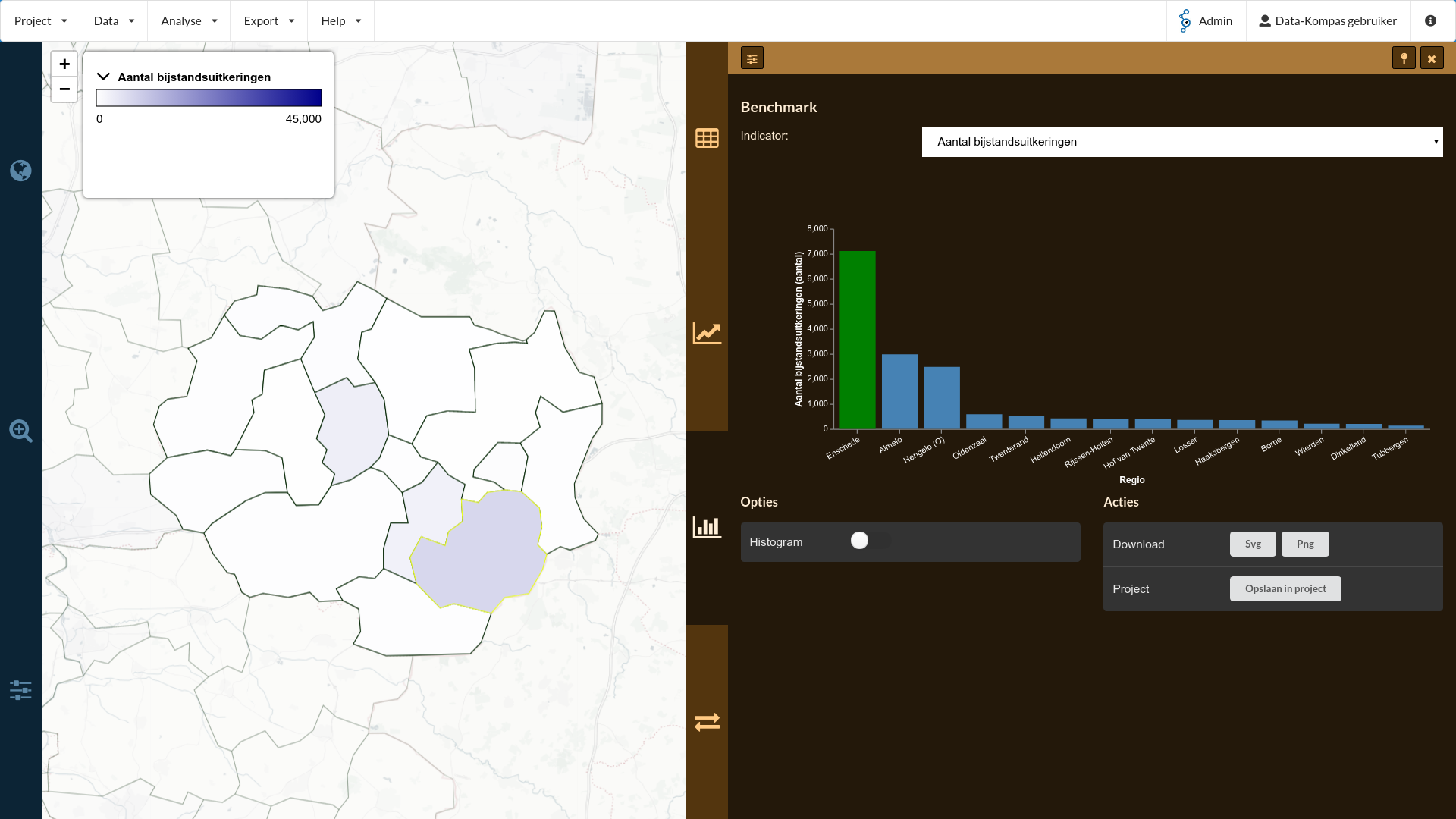
Maar, hoe zit het nu met de verdeling van het aantal bijstandsuitkeringen? Hiervoor kunnen we een benchmark doen. Het 3e oranje tabblad (icoontje ) geeft de mogelijkheid om de gemeenten te benchmarken. Door hierop te klikken zien we een histogram verschijnen, waarin de verdeling van het aantal bijstandsuitkeringen per gemeente te zien is. Doordat er een aantal gemeente zijn met een heel hoog aantal (door een hoog aantal inwoners) vertekend deze grafiek en lijkt het alsof er veel gemeenten zijn met weinig mensen in de bijstand. Hierover later meer.
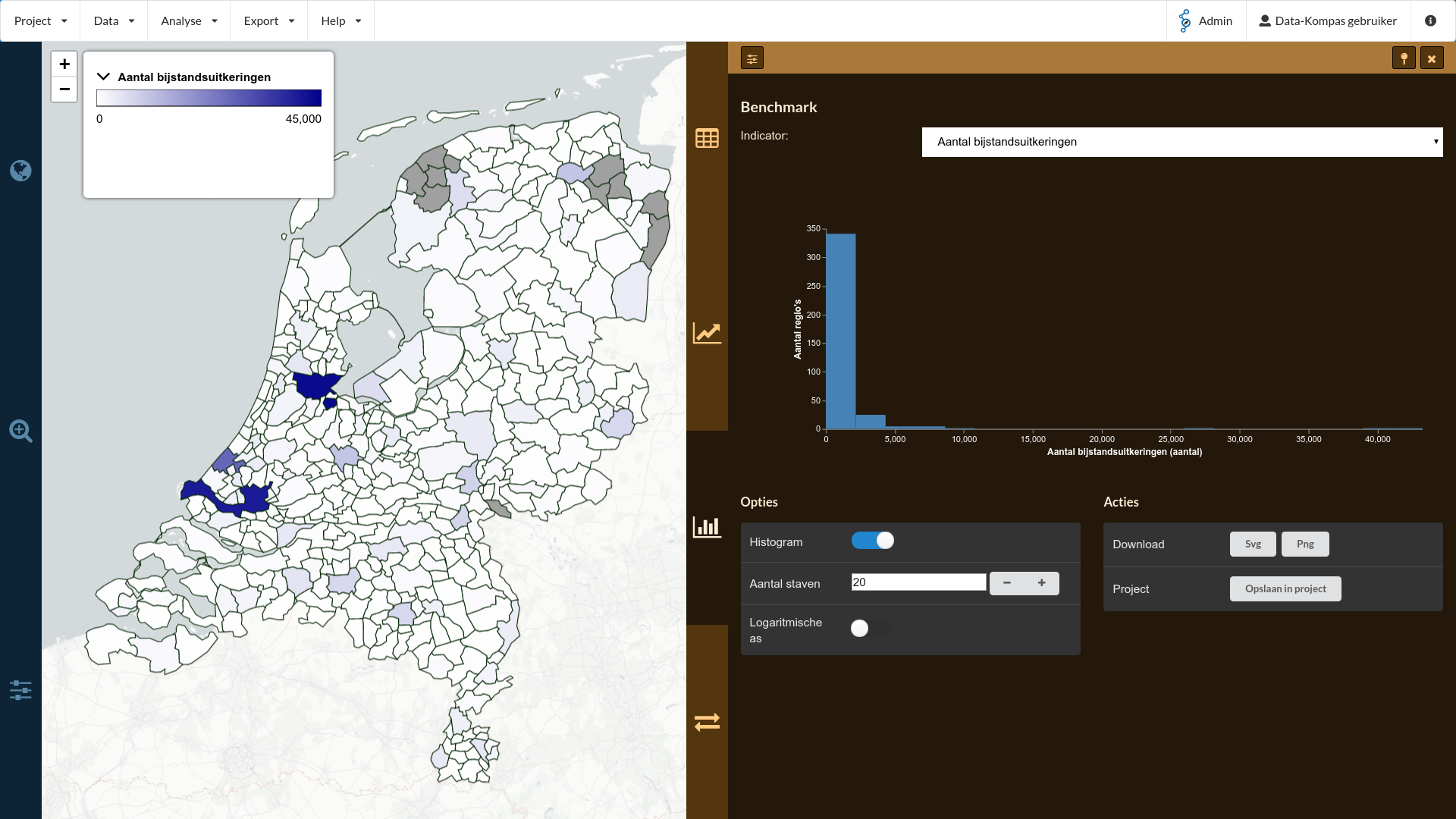
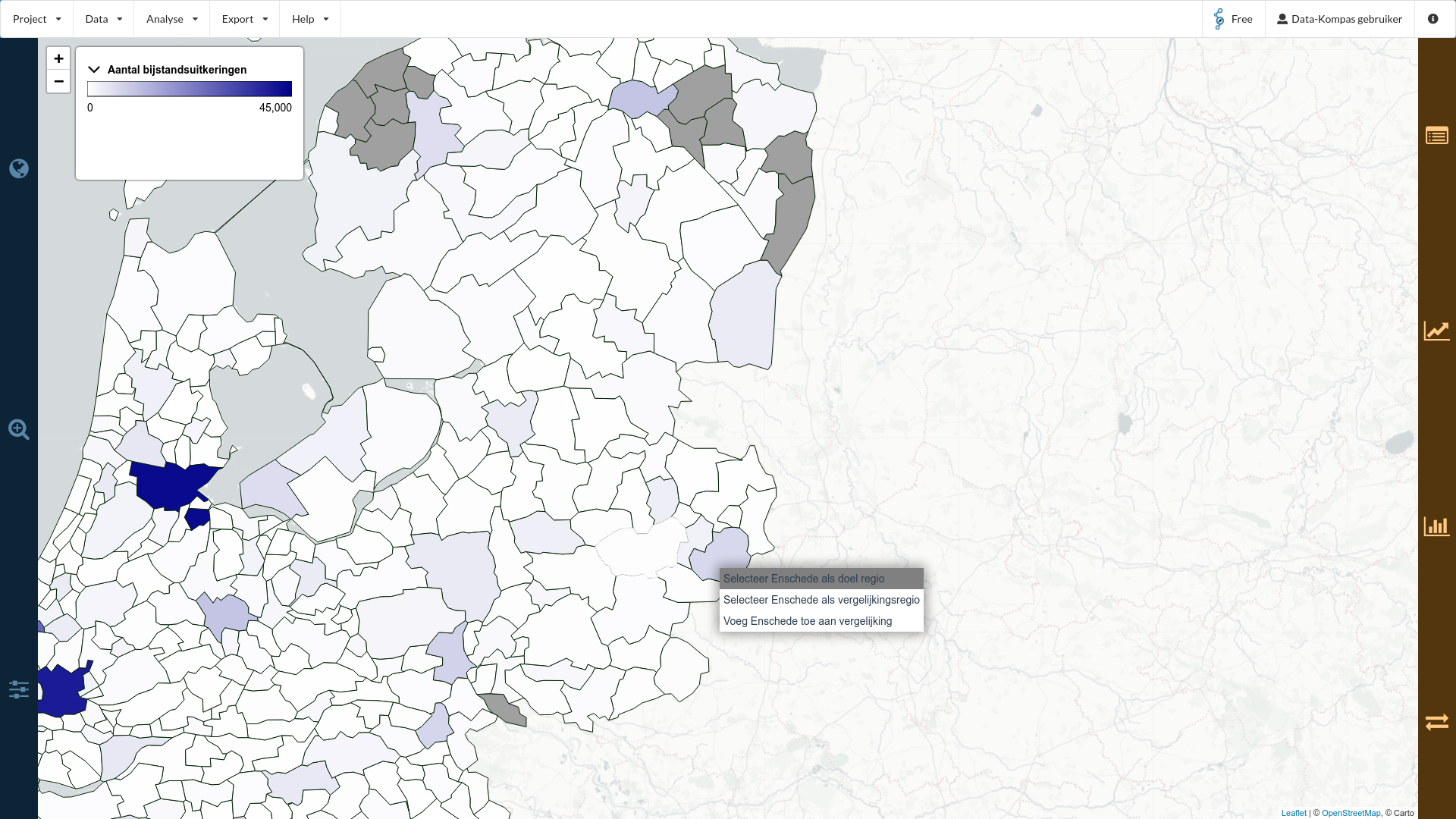
Stel nu, dat we het aantal bijstandsuitkeringen van een specifieke gemeente willen onderzoeken, bijvoorbeeld de gemeente Enschede. Om de gemeente Enschede te selecteren kunnen we of ‘rechtsklik gemeente Enschede op de kaart > selecteer als doel regio’, of door op het Regio tabblad (1e blauwtabblad, icoon ) te zoeken naar Enschede in het veld “Doel regio”. Na selectie zal er een gele rand om Enschede zichtbaar zijn.
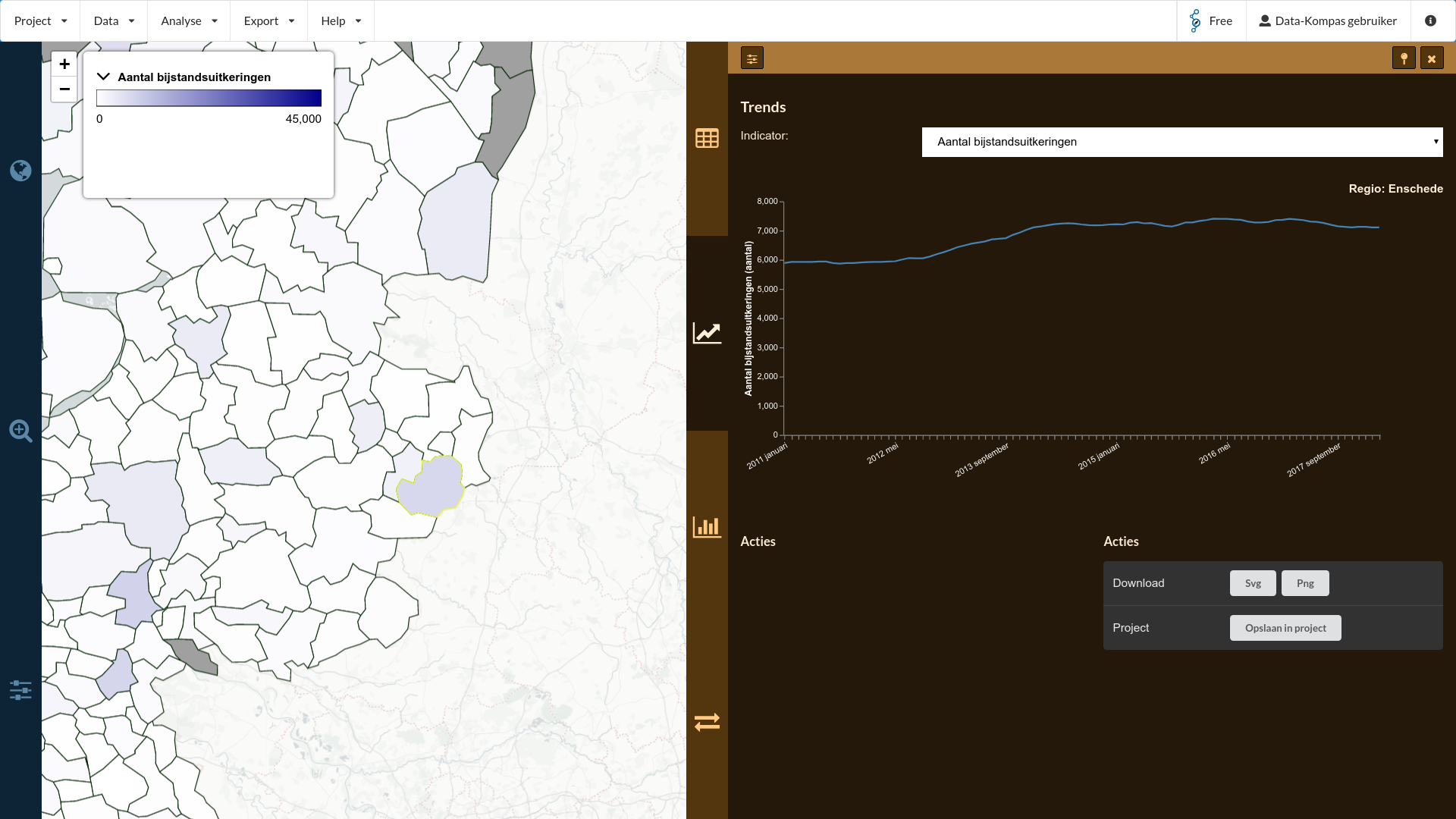
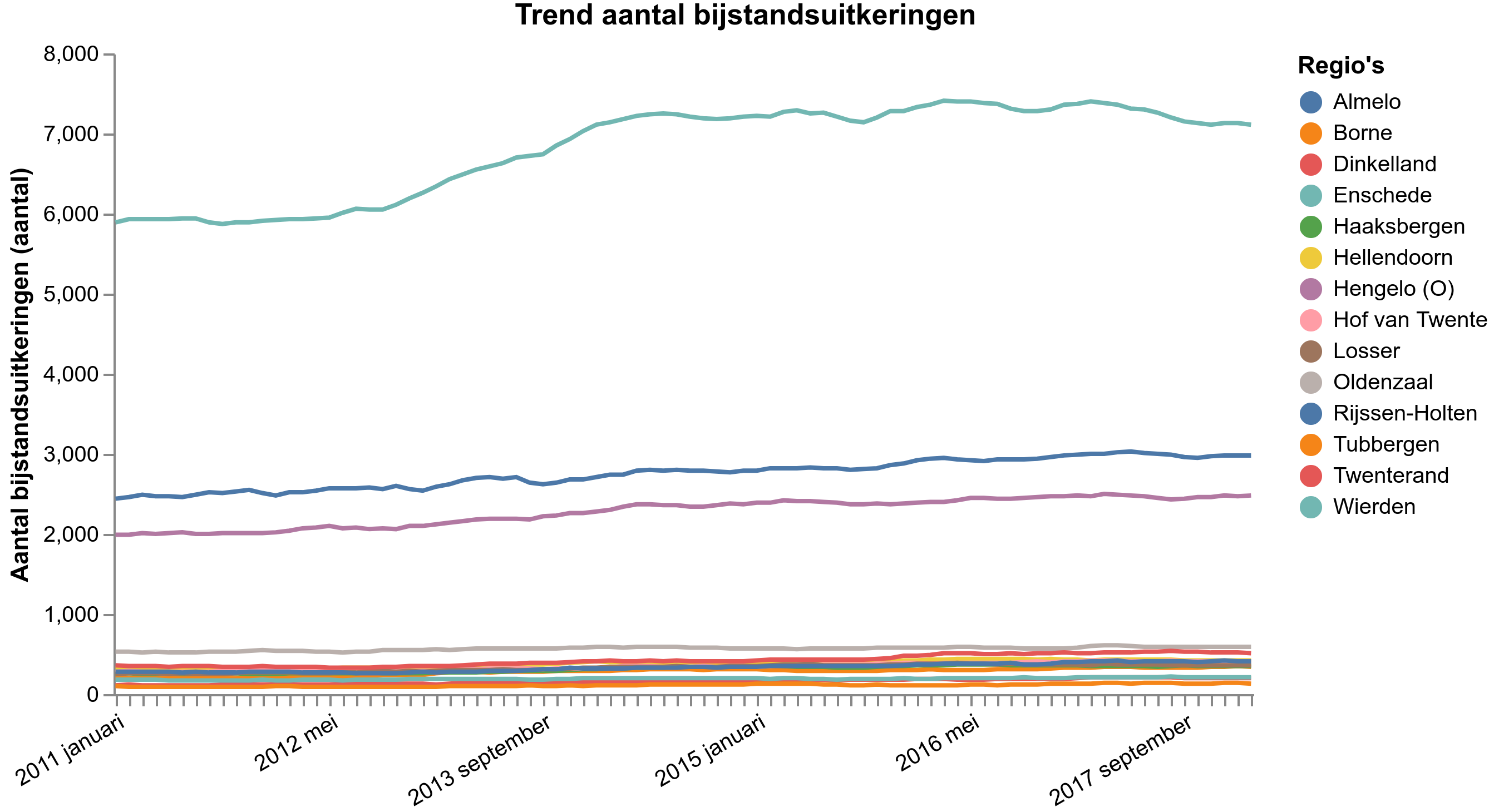
Als we nu het aantal bijstandsuitkeringen binnen Enschede door de tijd heen willen zien, kunnen we een trendgrafiek plotten. Deze is beschikbaar op het 2e oranje tabblad (icoon ). Doordat Enschede geselecteerd is, zien we direct de trend van Enschede.
Deze vergelijken met Regio Twente? In het regio tabblad (icoon ) kunt u bij “vergelijken binnen” Corop-regio Twente selecteren. Door dit te doen worden alle gemeenten binnen deze regio als vergelijkingsmateriaal gebruikt. Door nu weer het trend tabblad te openen zien we een trend van alle gemeenten binnen de vergelijking. Door met de muis over een gemeente te gaan, of over een lijn in de grafiek wordt zichtbaar welke gemeente hoe is gepositioneerd in de trend.
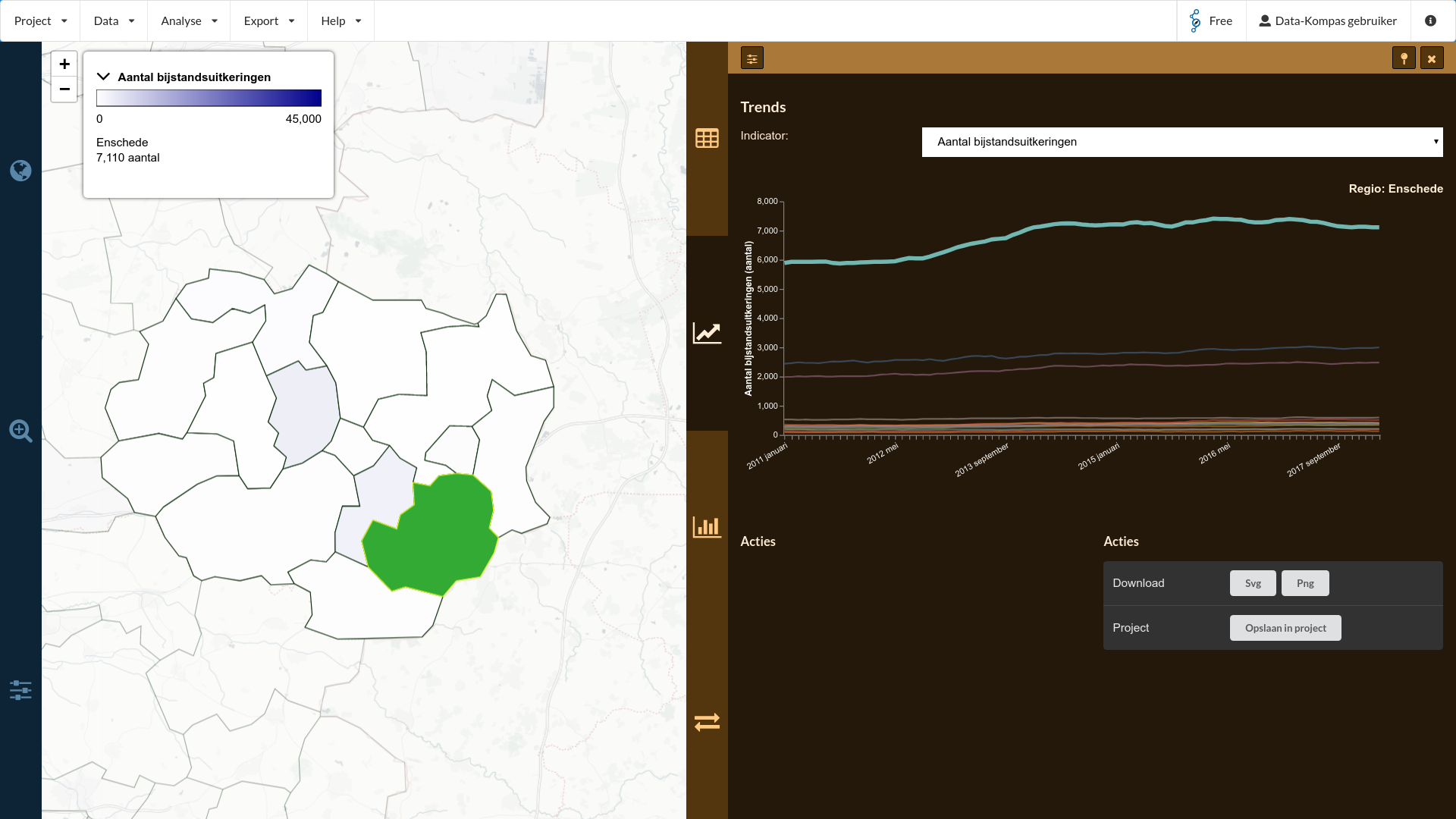
Dit resultaat kunnen we exporteren door op de knop ‘PNG’ te klikken in het export menu onder de grafiek, resulterend in onderstaande afbeelding. Wat we direct kunnen zien is dat in 2012 en 2013 het aantal bijstandsuitkeringen in Enschede sterk gegroeid is, terwijl dit niet in de omliggende regio’s het geval is. Waardoor zou dit kunnen komen?
Als laatst kunnen we ook van deze regio data een benchmark maken, die wellicht meer inzicht biedt dan het eerdere histogram. We zien nu in ieder geval duidelijk de aantallen per gemeente, maar ook deze grafiek vertekent doordat er grote verschillen zitten in de inwoners per gemeente.
Zo hebben we dus gemakkelijk de cijfers over de bijstand naar voren kunnen tonen en hier een aantal vergelijkingen mee kunnen maken. Wat ziet u nog in de cijfers? Zijn er andere regio’s die interessant zijn? Hoe zijn deze cijfers relevant voor uw organisatie? Of wellicht zijn de bijstandscijfers helemaal niet interessant, maar andere open data bronnen juist wel?
Met Data-Kompas kunnen dit soort analyses gemakkelijk over vele open data bronnen uitgevoerd worden. In komende blogs zullen we dieper in gaan op het normaliseren van data (zodat de gemeenten wel beter met elkaar te vergelijken zijn), het combineren van data, het bekijken van andere regio’s en overige interessante features die u in staat stellen om met de data aan de slag te gaan.
Wilt u ook zo gemakkelijk aan de slag met uw eigen data? Onze technische innovaties maken het makkelijk om ook uw data direct beschikbaar te stellen als indicator, zodat deze gebruikt kan worden voor trends, benchmarking, verbanden analyse, koppeling met open data, en nog veel meer. Mail naar info@data-kompas.nl, of bel naar 085 – 06 06 261 voor de mogelijkheden en een vrijblijvende offerte voor uw eigen data koppeling.
Lees meer...

Interpreteren van data is vaak een kunst op zich, zeker als u niet bekend bent met data analyses. Het kan lastig zijn om vat te krijgen op de gepresenteerde visualisaties, of om concrete conclusies te vormen op basis van een analyse.
Na een data analyse worden vaak visualisaties gepresenteerd, op basis waarvan verdere conclusies getrokken worden. Wij geven u 5 tips om hier mee aan de slag te gaan, en deze visualisatie resultaten op de juiste manier te interpreteren.
Het vak van data science houdt zich bezig met het vinden van patronen. Door data slim te ordernen, groeperen en transformeren kunnen verschijnen vele verschillende patronen uit de data. Data scientists focussen zich op het zichtbaar maken van deze patronen. Goede resultaten van een data analyse maken deze patronen zichtbaar en inzichtelijk.
In de statistiek is een bekend voorbeeld een scatterplot of spreidingsdiagram. In zo’n diagram zijn twee variabelen uitgezet tegen over elkaar en is elk stipje een specifiek datapunt. Als er sprake is van een linear verband is dit direct zichtbaar, doordat zich een wolk vormt met een specifieke vorm. Een patroon.
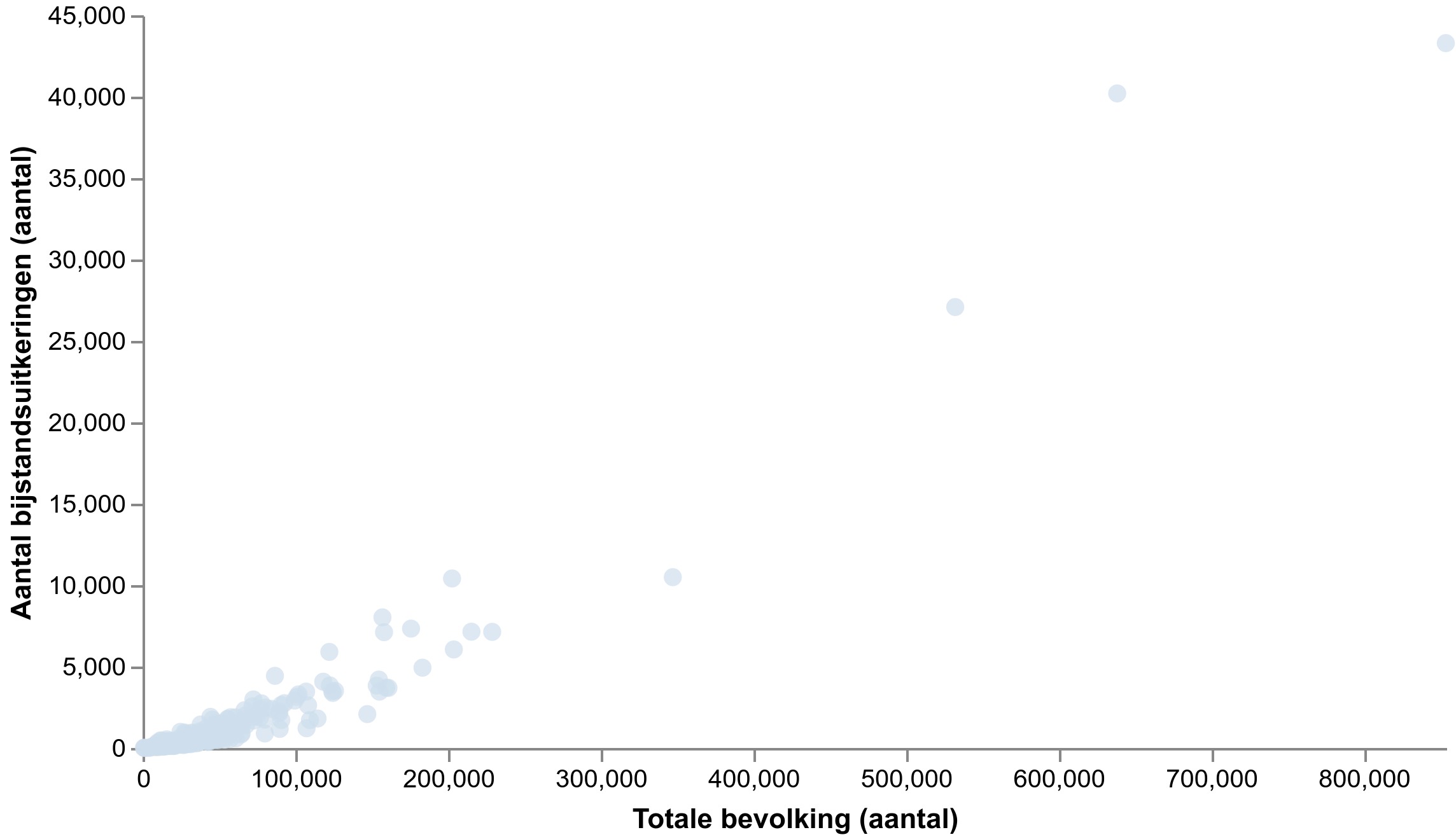
Bron: CBS, visualisatie gemaakt met Data-Kompas
Dit is een voorbeeld van zo een grafiek. We zien hier de relatie tussen het aantal inwoners “Totale bevolking” en aantal bijstandsuitkeringen, per gemeente. Dit wil zeggen dat elk bolletje een representatie is van een gemeente, en er in totaal net zoveel bolletjes zijn als gemeenten (bijna 400).
Kijkend naar patronen zien we het volgende:
Wat kunt u verder ontdekkken?
Het is aan beleidsmakers om deze patronen verder te interpreteren. In een trendgrafiek kunnen er dalende of stijgende lijnen zijn, wat een indicatie is dat de meetwaarde gedaald of gestegen in de tijd. Is dit gunstig voor uw organisatie, of juist niet?
In het voorbeeld van boven lijkt er een sterk verband gevonden te zijn voor het aantal bijstandsuitkeringen. Mooi! Dit kunnen we dus gebruiken om grip te krijgen op het aantal mensen in de bijstand.
Of niet? Het is vrij logisch dat het aantal inwoners in gemeenten een grote invloed heeft op het aantal bijstandsuitkeringen. Eigenlijk zegt bovenstaande grafiek dus niet zoveel, al zijn er wel duidelijke patronen zichtbaar.
Veel interessanter is het als we het aantal bijstandsuitkeringen per inwoner vergelijken met het percentage koopwoningen.
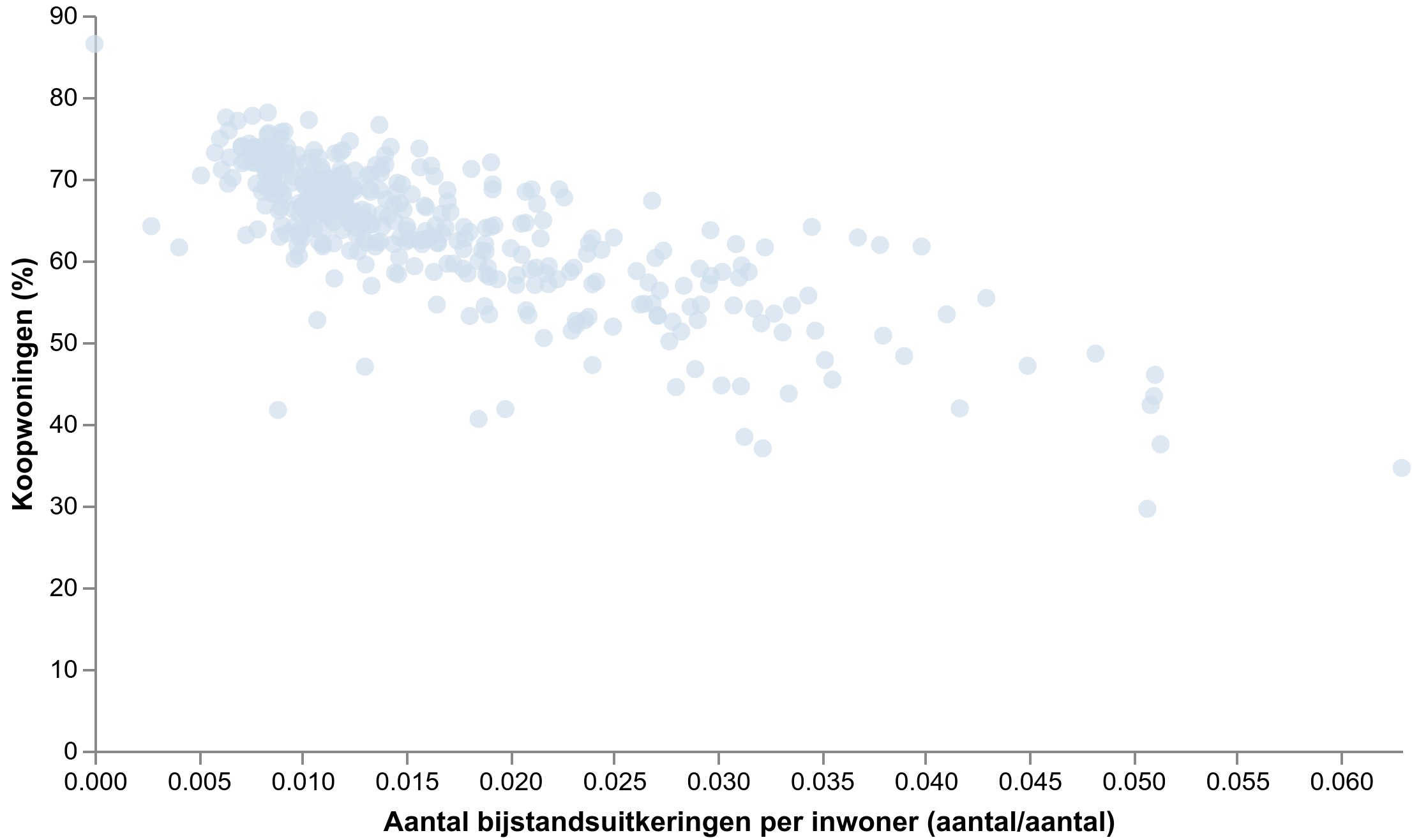
Bron: CBS, visualisatie gemaakt met Data-Kompas
Wat kunnen we hier uit concluderen? Opnieuw is er correlatie, maar is er een causaal verband?
Desalniettemin kunnen deze patronen vertekenen. Op basis van de operaties die een data analyist heeft uitgevoerd kunnen sommige patronen wel of niet onstaan.
Ons advies is om in ieder geval te letten op:
In een toekomstige blog zullen we dieper in gaan op deze valkuilen.
De belangrijkste identificaties van patronen vinden plaats doordat mensen met een specifiek beeld kijken naar de data. Experts binnen gemeenten kunnen wellicht patronen verklaren op het gebied van woningen en bijstand, of kunnen aantonen welke van de twee het gevolg is van de ander.
Deze domein kennis is van cruciaal belang om beleid te vormen op basis van deze visualisaties.
Onze laatste tip is om de discussie aan te gaan. Een beroemde quote:
“If you torture the data long enough, it will confess” - Ronald Coase
Tijdens een data analyse gaat het er niet om wie gelijk heeft. Het doel is om samen uit te zoeken wat de waarheid is, en op basis van deze waarheid conclusies te vormen. Elke visualisatie is slechts een bevooroordeelde representatie van de werkelijkheid, welke juist geinterpreteerd moet worden.
Door met zowel de data scientist, als domein experts in gesprek te gaan wordt duidelijk wat relaties zijn tussen visualisaties, welke elementen cruciaal zijn, en vooral welke data wel en welke data niet compleet juist is. Op basis van een specifieke bias zien sommige personen patronen juist wel of niet, of kunnen deze matchen met hun eigen kennis. Door de discussie aan te gaan wordt meer kennis zichtbaar uit de data.
Bent u geïnteresseerd in meer van deze tips & tricks of adviezen voor data interpretatie? De komende weken zullen wij meer bloggen over valkuilen bij data interpretatie, specifieke visualisatie typen, methoden om uw eigen data te vergelijken met open data, en nog veel meer! Volg ons op op twitter, voor alle laatste updates.
Of vraag informatie aan voor de introductie workshop ‘data en beleid’, om helemaal up-to-speed te zijn op het gebied van data en beleid.
Lees meer...
In onze nieuwe categorie “Uitgelicht” nemen we gave, interessante platforms onder de loep die iets met open data doen. Dit kan een publicatie platform zijn, een interessant research project, of een gave tool waarmee nieuwe inzichten verworven kunnen worden.
Vandaag: Het Open State foundation data portaal. Dit is zeker niet het enige data portaal in Nederland, zo zijn er ook data.overheid.nl, of dataplatform, of gemeente specifieke data platforms voor Groningen of Haarlem. Het open state portaal is gebaseerd op CKAN en lijkt dan ook veel op de ‘standaard’ portalen voor open data publictie van de overheid.
Dit data portaal blinkt uit op kwaliteit van de data. Elke dataset is ‘handpicked’ uit nationale, provinciale en gemeentelijke data portalen. Hierdoor is elke dataset afzonderlijk van hoge kwaliteit, de bronnen zijn goed beschreven en de data is ook degelijk bruikbaar. Iets dat via andere portalen nog wel eens een uitdaging kan zijn.
Bijvoorbeeld een dataset over wapenvergunningen. Via het open state portaal vinden we een dataset waarin de wapenvergunningen over verschillende jaren duidelijk zijn weergegeven. We vinden data vanaf 2014, tot en met 2016 en er is een gecombineerde dataset die 2014 tot en met 2016 combineert. Ook is deze data direct downloadbaar als CSV bestand, en goed gestructureerd. Via data.overheid.nl vinden we twee datasets. De eerste over 2015 en de tweede over de eerste helft van 2016. Ofwel, we zouden extra op zoek moeten gaan naar de wapenvergunningen in 2014 en 2e helft 2016 om de complete set boven tafel te halen. Ook zouden we tijd moeten investeren om de datasets aan elkaar te koppelen en hier 1 dataset van te maken, als de dataset van open state foundation dit niet al gedaan had.
Een andere dataset is de verdeling van het gemeentefonds, met een groot CSV bestand dat de verschillende indicatoren aangeeft voor de verdeling. Ook hier is het voordeel dat de data over meerdere jaren in 1 dataset gevangen is. De data is van hoge kwaliteit en er zijn geen tijdrovende data opschoon stappen nodig voordat je er daadwerkelijk iets mee kunt.
Ons advies is om zeker eens door de data van open state heen te bladeren. De 64 datasets zijn makkelijk om door heen bladeren en doordat ze allemaal makkelijk te downloaden zijn kun je er snel mee aan de slag en verschillende dataset eens nader bekijken.
Heb jij iets interessants gezien waar wij over zouden moeten bloggen? Stuur een mail naar uitgelicht@data-kompas.nl!
Lees meer...

Veel organisaties zien de potentie van het gebruik van open data. De schat aan informatie die beschikbaar is op alle verschillende portalen kan inzichten geven die het beleid verder kan onderbouwen.
Toch is een veelvoorkomend probleem dat organisaties niet weten waar ze moeten beginnen. “Hoe gebruik ik die data dan?” is een veel gehoorde vraag. Wij zien dit niet als een probleem dat veroorzaakt door te weinig gebruik van data binnen de organisatie. Organisaties denken bij het woord “data-gedreven beleidsondersteuning” direct aan data en hoe deze het beste in te zetten. Hierdoor wordt vaak de “waarom?” vraag uit het zicht verloren. Door alleen naar de data te kijken is het lastig om concrete vraagstukken te beantwoorden.
Ons advies: begin bij de vraag! Er spelen continu vraagstukken die vragen om sturing. Vraagstukken waarvan niet zo goed duidelijk is hoe deze aangepakt kunnen worden. Vraagstukken waarbij aannames worden gemaakt die niet per se hoeven te kloppen. Ga eens na binnen de organisatie, welke concrete vraagstukken spelen er eigenlijk? Welke aannames maken wij die niet (of slecht) gevalideerd zijn?
Na een korte inventarisatie van verschillende vraagstukken kan begonnen worden met stap 2: kies een enkel vraagstuk specifiek en houdt een korte brainstom over:
Op basis van deze inzichten kan er gericht gezocht worden naar data die beschikbaar is. Pas als er relevante data gevonden is en de vraagstelling helder is kunnen er daadwerkelijk inzichten uit de data verkregen worden die de organisatie verder kan helpen.
Hulp nodig om hier mee te starten? Met de Data-Kompas decision room helpen wij om nieuwe inzichten te bieden op een concreet vraagstuk op de lossen, met gebruik van een combinatie van eigen data en open data.
Lees meer...

Afgelopen 22 juni was er weer een gebruikersbijeenkomst van data.overheid.nl. Tijdens deze bijeenkomsten worden de laatste ervaringen gedeeld op het gebied van open data bij de overheid, dit keer met als thema ‘High-value datasets’. Een uitgebreid verslag van alle presentaties is hier te vinden
Tijdens de bijeenkomst en de presentaties is er veel ruimte voor vragen. Dit keer gingen veel vragen en opmerkingen over de verschillende standaarden. Om de ‘High-value datasets’ mogelijk te maken worden veel standaarden ontwikkeld en gebruikt. Anders dan de DCAT standaard gebruikt door verschillende catalogi zijn deze standaarden erop gericht om data velden te harmoniseren, zodat deze beter vergeleken kunnen worden.
Het is goed dat hier veel aandacht voor is. Het combineren en kunnen vergelijken van verschillende datasets van verschillende gemeenten kan veel nieuwe inzichten geven. Een voorbeeld waarin dit succesvol is zijn de Iv3 data, met o.a. de begroting van de gemeenten. Hierdoor zijn begrotingen van verschillende gemeenten goed te vergelijken, bijvoorbeeld via open spending.
Een andere discussie over data kwaliteit werd gestart door de presentatie van Chris van Aart (2COOLMONKEYS). Een van zijn stellingen: “Ik ben meer kilo’s aangekomen dan dat er goede datasets zijn”. Tijdens hackatons en kennisbijeenkomsten zijn er vrijwel altijd goede lunches, maar vaak ontbreekt het daadwerkelijk aan de goede data. Dit zorgt voor veel problemen bij de hergebruikers van open data doordat data kwaliteit altijd eerst gevalideerd moet worden.
Ook wij merken vaak data data kwaliteit een uitdaging is, niet alleen binnen de overheid. Door het gebrek aan data kwaliteit hebben data analysten vaak veel werk aan het verbeteren van de data. Ons advies is altijd om deze processen vanaf het begin al beter te automatiseren, zodat deze minder foutgevoelig worden.
Al met al zien we dat de trend op het gebied van open data verschuift van het publiceren en verzamelen van veel data naar het verbeteren van de kwaliteit van de data, in onze ogen een essentiële stap voor effectief gebruik van data binnen een organisatie.
Lees meer...
Kijkt uw organisatie ook reikhalzend uit naar alle mogelijkheden die data met zich mee brengt? Of bent u juist benieuwd wat u met data zou kunnen doen? U bent zeker niet de enige!
Door de laatste ontwikkelingen op het gebied van data zijn er eindeloze mogelijkeden. Vanuit de overheid komen er meer en meer open data beschikbaar, welke vrij hergebruikt kunnen worden. Daarnaast verzamelen organisaties hun eigen waardevolle data. Data over klanten, data over vestigingen van de organisatie, data over producten en omzet, en er zijn vele andere mogelijkheden. Maar hoe gebruikt u deze data nou effectief?
Door deze overvloed aan data zien veel organisaties door de bomen het bos niet meer. Het is lastig om verschillende bronnen de analyseren, te visualiseren en vooral, in context te plaatsen. Wat betekent dit? Welke conclusies kan ik uit deze data trekken? De mogelijkheden zijn eindeloos, maar worden vaak niet gezien en daardoor niet benut.
Wij zoeken in ons dagelijks werk de kansen op en gaan samen met organistaties aan de slag om data optimaal te benutten. Geen makkelijke taak, maar het blijkt altijd van onschatbare waarde te zijn. Met deze blog delen wij onze ervaringen, waar u weer van kunt leren.
Geinteresseerd wat (open) data voor u kan betekenen? Volg ons op twitter of LinkedIn, of neem contact met ons op!
Lees meer...